
There is a GitHub repo sitting at 56,000 stars right now. It has nearly 9,000 forks. The name is learn-claude-code, and the people who built it describe the whole thing in five words: “Bash is all you need.”
That line sounds either profound or ridiculous depending on how much time you have spent trying to understand AI coding agents. Once you get into the repo, you realize it is both things at once, and that is kind of the point.
Link to the repo: https://github.com/shareAI-lab/learn-claude-code
What Is This Repo Even For?
Short answer: it teaches you to build the thing around the AI, not the AI itself.
Here is the longer version. When you use Claude Code or any AI coding tool, there are two separate pieces working together. The first is the model itself, the actual intelligence trained by Anthropic on billions of lines of code and text. The second is everything surrounding it: the loop that keeps asking the model questions, the tools that let it read files and run commands, the system that manages memory so it does not forget what it was doing. That second piece is called the harness.
Most people learn about the model. This repo teaches you the harness.
The Big Idea That Changes How You Think About AI Agents
The repo opens with a history lesson, and it is one worth paying attention to.
In 2019, Tencent’s AI “Jueyu” played 5v5 Honor of Kings against professional players and won. The pros won exactly 1 game out of 15. One day of training for that AI was equivalent to 440 years of human play. It learned team coordination, hero matchups, real time adaptation, all of it, from scratch. No one wrote rules telling it what to do. The model figured it out.
Same year, OpenAI’s Five beat the world champions at Dota 2 after playing 45,000 years worth of games against itself in 10 months. Again, no scripted strategies. Just a model that learned.
The repo draws a straight line from those game playing AIs to Claude Code and GPT. The architecture is the same, a model placed in an environment, given tools to perceive and act. The only thing that changed is the scale and what the model learned.
What that means for you as a developer/as a learner? you are not in the business of writing intelligence. You are in the business of building the environment. The repo calls that environment the harness.
“Prompt Plumbing” and Why It Does Not Work
Before getting into what the repo actually teaches, it spends some time on what you should stop doing. This part is worth reading closely.
The team describes the no-code “AI agent” platforms you see everywhere right now, the drag-and-drop workflow builders, the node graph orchestration tools, as “Rube Goldberg machines.” Their argument: stacking procedural logic and wedging an LLM in the middle does not create an agent. It creates a fragile pipeline that breaks when the input changes slightly.
The phrase they use is “shell script with delusions of grandeur.” That is harsh, but the logic behind it is solid. If intelligence comes from training, you cannot engineer your way to the same result with if-else statements. You can paper over it for simple tasks. But you cannot generalize.
This is the mindset shift the repo is trying to create. Your job as a harness engineer is to give the model a clean, capable environment. Tools it can use. Knowledge it can access. Clear permission boundaries. Then get out of the way and let the model decide.
The Core Loop, Explained Simply
Every session in this repo builds on one 15-line piece of Python. Understanding it is the whole game.
You send the model a list of messages. The model responds. If the response says “I want to use a tool,” you run that tool, append the result to the message history, and send everything back to the model. You keep doing this until the model stops asking for tools and just returns text.
That is it. That while loop is the foundation of every AI coding agent you have ever used.
while True:
response = call_the_model(messages)
if response wants to stop:
return response.text
results = run_whatever_tools_it_asked_for()
append results to messages
The repo’s job is to show you everything you build around this loop to make it actually useful in the real world.
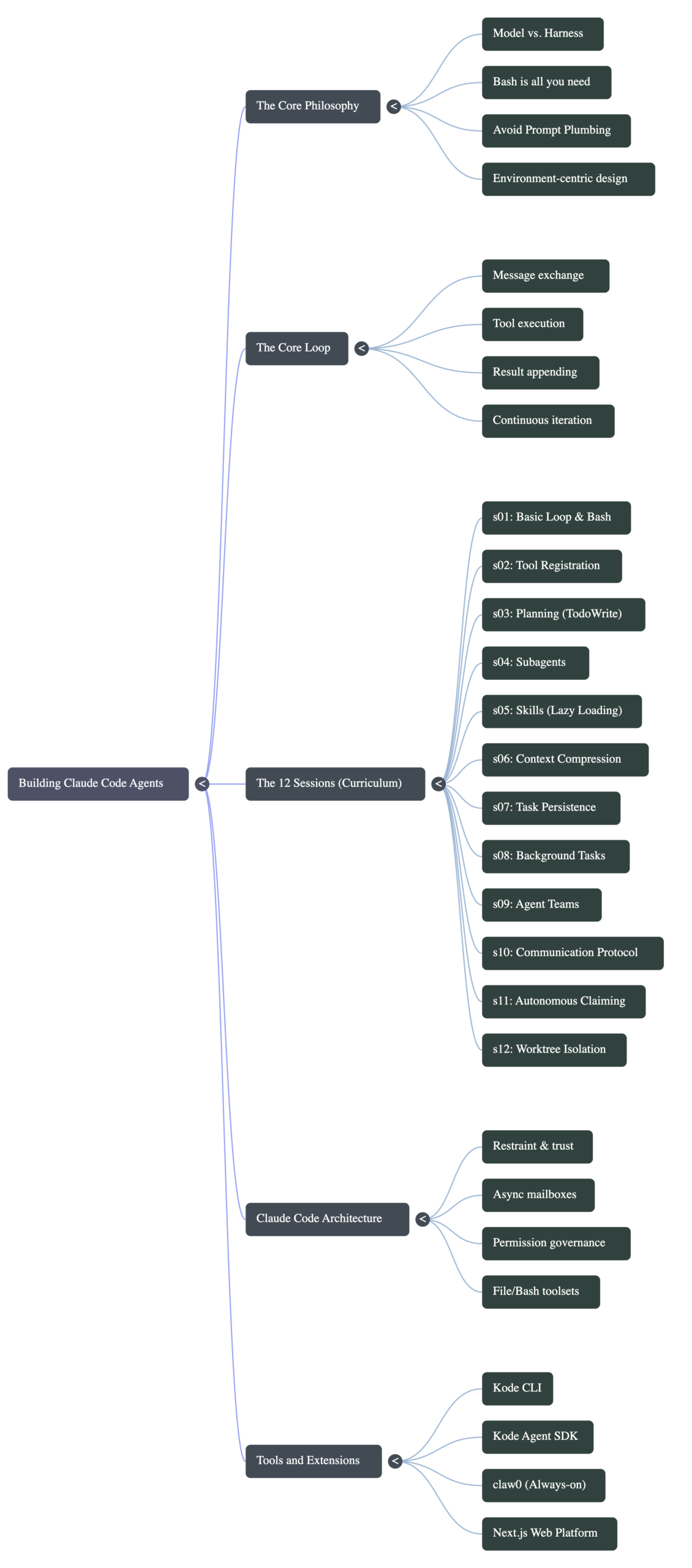
The 12 Sessions, One by One
The curriculum is organized into 12 Python files, named s01 through s12. Each one adds exactly one new concept. None of them changes the core loop.
Session 1 is the loop itself, with just one tool: a bash command runner. That is enough to make a working agent. Minimal, yes. But functional.
Session 2 adds more tools and shows you the pattern for registering them. The insight here is that adding a new tool is literally just adding one entry to a dictionary that maps tool names to Python functions. The loop does not care how many tools exist. It just checks the map.
Session 3 introduces planning. Without a to-do list, the agent drifts. It does a bit of one task, then gets distracted by something in the output, then forgets what it was originally trying to do. Adding a TodoWrite tool that the agent uses to write down its steps before executing them is enough to double task completion rates. Simple fix, big results.
Session 4 is subagents. When a task is big enough to need a fresh context, you spawn a child agent with its own clean message history. The parent keeps its workspace tidy. The child handles the messy work. This is directly how Claude Code handles long or complex tasks.
Session 5 covers skills. Instead of cramming all your documentation and domain knowledge into the system prompt at startup, you let the agent pull what it needs on demand. The file format is just a markdown file with a description at the top. When the agent needs it, it requests it. The harness injects it as a tool result. Lazy loading for knowledge.
Session 6 tackles context compression. Eventually the message history gets too long. The model’s context window fills up. You need a strategy to summarize and compress history without losing the thread of what is happening. The repo implements a three-layer approach: recent messages stay intact, older messages get summarized, very old messages get dropped except for key decisions.
Session 7 builds a task system that lives on disk. Goals persist between runs. Tasks have dependencies. You can see what finished, what is in progress, what is blocked. This is the foundation for multi-agent work.
Session 8 adds background tasks. When you tell the agent to run a test suite or a build that takes two minutes, you do not want the whole loop to freeze. Daemon threads handle slow operations while the main agent keeps working and gets notified when something finishes.
Session 9 creates agent teams. One lead agent and several teammates, each running their own loop, talking to each other through a shared mailbox implemented as JSONL files. The lead delegates. Teammates execute. Results get reported back.
Session 10 defines the communication protocol between teammates. Without shared rules, agents talk past each other. This session establishes a request-response pattern that handles negotiation and shutdown cleanly.
Session 11 makes agents autonomous. Instead of waiting for the lead to assign tasks, each teammate wakes up on its own idle cycle, scans the task board, and claims something to work on. No micromanagement needed.
Session 12 adds worktree isolation. Each agent task gets its own Git worktree, which is basically its own working directory. No two tasks step on each other’s files. Parallel execution becomes safe.
Why Claude Code Specifically?
The repo’s authors are pretty direct about this. They chose Claude Code as the subject because it is, in their words, the most elegant agent harness they have seen. Not because of clever tricks, but because of restraint.
Claude Code does not try to impose workflows on the model. It does not second-guess Claude with elaborate decision trees. It provides tools, context management, and boundaries, then trusts the model to figure out the rest.
Stripping Claude Code to its components, the repo lists: one agent loop, a set of bash and file tools, on-demand skill loading, context compression, subagent spawning, a task system, team coordination with async mailboxes, worktree isolation, and permission governance.
That is the full architecture. Every piece is a harness mechanism. Claude, the model, provides the intelligence. The harness provides the workspace.
Who Is This For?
If you have never written an AI agent before: start at s01. Run the file. Watch it work. Then move forward one session at a time. The code is short enough that you can read the whole thing before running it.
If you already use Claude Code or Cursor and want to understand what is happening under the hood: the architecture diagram in the README will click fast. The sessions fill in the details.
If you want to build your own AI coding agent or adapt these patterns to a different domain: the repo is explicit that the harness patterns generalize. A farming agent is a model plus soil sensors plus irrigation controls plus crop knowledge. A hotel operations agent is a model plus booking system plus guest channels plus facility APIs. The loop stays the same. The tools change.
The Web Platform Is a Nice Touch
Beyond the Python files, the repo includes a Next.js web app you can run locally. It has interactive visualizations and step-through diagrams for each session. Not required, but useful if you learn better visually than by reading code.
cd web && npm install && npm run dev
That spins up at localhost:3000 and shows you animated breakdowns of how each session works.
What Comes After the 12 Sessions
The repo points to two production tools from the same team once you finish the curriculum.
The first is Kode CLI, an open-source coding agent CLI you can install with npm. It supports multiple models including GLM, MiniMax, and DeepSeek, not just Claude.
The second is Kode Agent SDK, which lets you embed agent capabilities directly into your application. The official Claude Code SDK requires a separate terminal process per user, which gets expensive at scale. The Kode SDK runs without that overhead and can be embedded in backends, browser extensions, or embedded devices.
There is also a sister repo called claw0 that teaches the “always-on” version of the same patterns. Instead of running an agent on demand and closing it when done, claw0 adds a heartbeat mechanism, where the agent wakes up every 30 seconds to check if there is work, and a cron system, where the agent can schedule its own future tasks. Add multi-channel messaging support and a persistent memory system, and you get something closer to an AI assistant that is always running rather than a tool you invoke.
The Quick Start If You Want to Jump In Now
git clone https://github.com/shareAI-lab/learn-claude-code
cd learn-claude-code
pip install -r requirements.txt
cp .env.example .env
Open the .env file and add your Anthropic API key. Then:
python agents/s01_agent_loop.py
That is your first agent. It can run bash commands. Give it something to do.
The Philosophy, Summed Up
The repo keeps coming back to one sentence: “The model is the agent. The code is the harness. Build great harnesses.”
That reframing is more useful than it sounds. Most AI development tutorials are obsessed with prompting, with how to get the model to do what you want through clever instructions. This repo ignores that almost entirely. The assumption is that the model is already capable. Your job is to give it hands, eyes, and a workspace it can actually use.
The 12 sessions are a masterclass in exactly that. Each one solves a real problem: agents that drift without plans, contexts that overflow, tasks that need isolation, teams that need coordination. Each solution is simple enough to fit in a few hundred lines of Python.
The model is already smart. Your job is to build the world it operates in.
Start here: https://github.com/shareAI-lab/learn-claude-code